A Quick Intro to Azure Data Factory & Its Key Features
ADF is a cloud-based integration service for orchestrating and automating data movement and data transformation with 90 maintenance free connectors built-in at no added cost. Easily construct ETL and ELT processes in a visual environment or write your own code.
Cut down operating expenses and capital expenditures and save precious time with these key features:
- No code or maintenance required to build hybrid ETL and ELT pipeline within the Data Factory visual environment.
- Cost efficient and fully managed serverless cloud data integration tool that scales on demand.
- SSIS integration runtime to easily rehost on-premises SSIS packages in the cloud using familiar SSIS tools.
- Azure security measures to connect to on-premises, cloud-based and software-as-a-service (SaaS) applications with peace of mind.
Remembering ADF Past (v1) to Understand ADF Present (v2)
Azure Data Factory v1 went into public preview on 28th Oct 2014 and then released for general available on 6th Aug 2015. Back then, it was a limited tool for processing data, but it couldn’t hold up in front of SQL Server Integration Services (SSIS) features. In early days of Azure Data Factory, you needed to develop solutions in visual studio, and even though there was some improvement made for diagram view, there was lot of JSON editing that needed to be done.
At MS Ignite 2017, Microsoft introduce the new updated version of ADF. It was launched as v2 due to it many new features and capabilities making it was almost an entirely new product. You could now Lift and Shift your on-premises SSIS solution to Azure very easily. ADF v2 went into public preview on 25th Sept 2017.
The most important updates were things like branching and looping and even running pipeline on scheduled time clocks or in regular intervals. Azure Data Factory v2 even become more popular when the new Visual Studio went into public preview on 16th Jan 2018. Some more feature went into public preview on 27th Jun 2018 such as DRAG and DROP feature.
What is ETL?
As said above, ADF is an ETL and ELT tool for Data solution. ETL stands for Extract, Transform and Load. ETL provides the method of moving the data from various sources into a data warehouse. The image below illustrates the 3 stages of data flow in ADF i.e., E – Extract, T – Transform and L – Load.
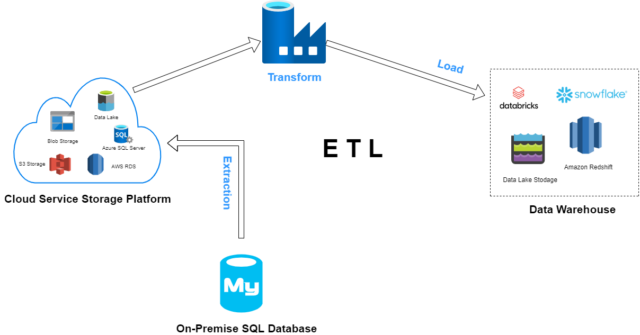
The ETL process collects unstructured data from On-Premises SQL Database. Data is extracted into a cloud service storage platform for data transformation as per requirements. ADF has the functions and activities which transform the unstructured data into structured data for BI tool and Analytics. With the help of ADF, the transformed data is then loaded into data warehouse or any cloud storage.
ETL is a process that uses cloud storage services for staging environments such as Blob, Data Lake, S3 storage and so on. Staging environments are like workspaces for actual data with its complete properties to test before the actual data is stored.

Unleash the Potential of Power Platform With a Center of Excellence
In this case raw data is staged from On-Premise’s server and stored into cloud storage. The transformation job is done on RAW data stored in source destination i.e., cloud storage. After that it is stored into data warehouses such as Snowflake or Databricks.
Now let’s see how all these stages are connected to each other and what functions are used to transform the data in ADF.
Connection and workflow of ADF
The image below is an example of an ADF copy workflow and the components and services used to orchestrate the task. Let’s go through the flow and learn each part involved in an ADF transformation job.
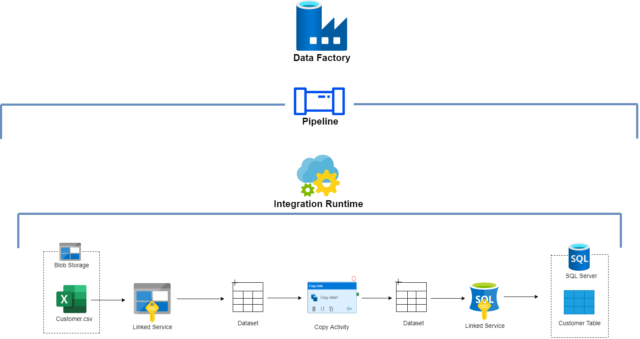
This example activity uses two Datasets as input source and output destination (sink) and these Datasets are connected using Linked services. Linked services are used to connect the actual storage location of data on both the source end and destination end. Integration Runtime binds this complete workflow and to automate or perform this task with single click, you will create a Pipeline.
Pipeline
As shown in the above image, pipeline is a logical grouping of activities. Activities deploy together to execute a specific task. Pipeline has lots of activities such as Get Metadata, For Each, Copy Activity, etc., to perform data transformation tasks. In this scenario, “copy activity” is used to copy data from the data source store to destination store.
Integration Runtime
Commonly known as IR, Integration Runtime is the heart of Azure Data Factory. IR provides the computer resources for data transfer activity and for dispatch of data transfer activities in ADF. There are 3 types of Integration Runtime – Azure IR, Self-hosted, Azure-SSIS.
Blob Storage
This cloud storage provided by Microsoft stores massive amount of unstructured data, such as text or binary data. As you can see, the Customer.csv file with unstructured data of customer details is stored in blob storage.
Linked Service
Linked services connect data source and destination. In this example, the linked service connects to our data source i.e., blob storage. Data source can be an Azure blob storage, Azure SQL Database, or on-premises SQL Server.
Dataset
Dataset is used to connect to the data source and destination via linked services. Datasets are created based upon the type of data source and destination you want to connect.
As you can see above, on the source side a blob storage type of dataset connects via linked service to the actual location of data in blob storage. On the destination side, an SQL server type of dataset connects via linked service, pointing to the exact table location in database to storage data.
Copy Activity
The activity in this pipeline is used to copy data between different data stores, and in this case transform the data format as required in the destination store. Datasets are provided to this activity as input and output source.
So, with this you can understand ADF is the umbrella for all the components – such as Linked Service, Datasets, Integration Runtime – fused together in Pipeline Activity to produce transformed data for analytical tools such as Power BI and HDInsight for planning business outcomes.
Why Perficient?
Our more than 20 years of data experience across industries gives us a deep understanding of current data trends. As an award-winning, Gold-Certified Microsoft partner and one of just a handful of National Solution Providers, we are a recognized cloud expert with years of experience helping enterprises make the most out of the Microsoft cloud.