Between April 9 and April 11, 2026, a platform issue affected the Azure Health Data Services FHIR service in some regions. The official symptom was that when different resource types shared the same resource ID, reads or updates could fail and the most recent version might not be returned as expected. Microsoft fixed the issue on April 11 by changing key comparison logic from string-based resource-ID comparison to a proper ResourceKey comparison. The public hotfix trail shows up in the FHIR server PR merged on April 11, the 4.0.728 release on April 17, and the official Learn release notes updated on April 30.
Executive summary
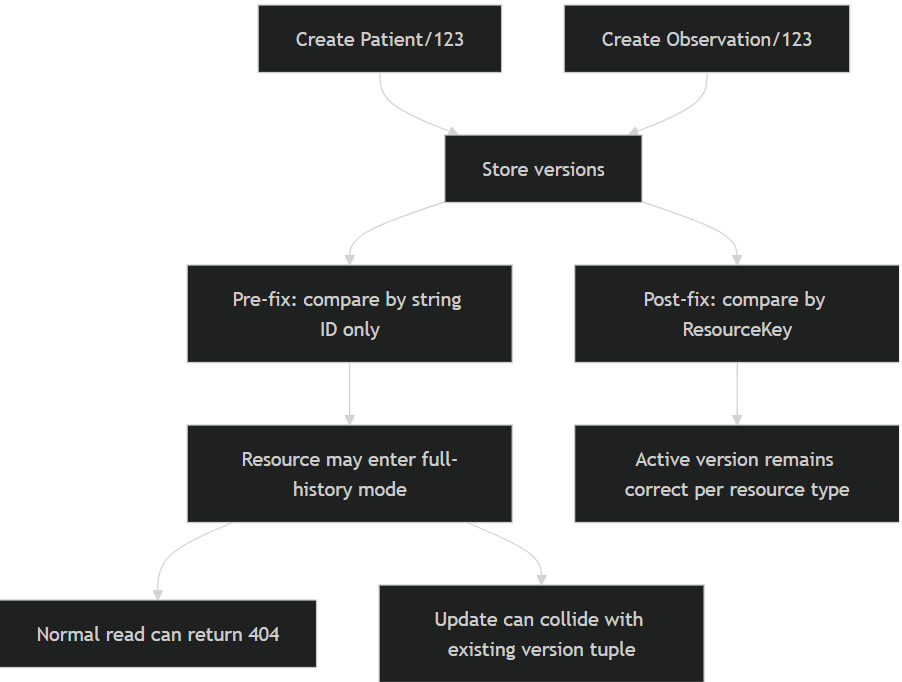
This was not just a cosmetic bug. It touched one of the most sensitive areas in any managed API platform: what the service considers the “current” version of a resource. Microsoft’s April release notes say customers could see errors on access or update when different resource types shared the same resource ID, and that the most recent version might not be returned correctly. The corresponding PR and release trail explain the mechanics more clearly: the SQL data store could leave affected resources in what the team called a “full history mode,” where the highest version is incorrectly marked as historical and no active version remains.
From an engineering standpoint, that means a routine read can look like a missing resource, and a routine update can turn into a version-collision problem. Microsoft’s own PR notes say the broken state could cause normal queries to return HTTP 404 unless a caller explicitly requested a historical version, and could block updates because the service would try to recreate a resource/version combination that already existed.
Background
The Azure Health Data Services FHIR service is a managed PaaS FHIR endpoint with REST APIs, RBAC, and audit logging. Its versioning model matters because history is a first-class feature: by default, the service uses the versioned policy, which stores history and increments meta.versionId. Microsoft’s versioning doc also makes clear that history can be queried at the resource, type, or system level, which is exactly why a bug in active-versus-history classification becomes operationally significant.
This matters even more because the service is designed for healthcare and regulated workloads, where data correctness, auditability, and deterministic read behavior are not nice-to-have properties. They are table stakes. The FHIR service overview and logging docs both lean into that point: audit trails, controlled access, and consistent REST behavior are part of the service contract.
Detailed walkthrough
Microsoft’s public April release note gives the symptom and the fix in a single line: some customers saw versioning errors when different resource types shared the same resource ID, and the fix was to replace string-based ID comparison with proper ResourceKey comparison. The PR merged on April 11 goes further and is the strongest technical source for root-cause analysis: the SQL data store could leave resources in a state where the highest version had IsHistory: true, so the resource lost its active version altogether.
The same PR spells out the failure mode in plain terms. First, resources could become non-updatable because the service would try to recreate the combination of resource type, resource ID, and version 1, colliding with existing constraints. Second, because there was no active version left, normal queries could return HTTP 404 unless a historical version was requested directly. The PR also names two situations where the bug could happen: import flows and parallel bundles containing resources of different types that reuse the same resource ID.
A minimal repro, reconstructed directly from Microsoft’s documented symptom and the PR’s technical description, looks like this:
A representative request sequence for a lab validation can be expressed as follows. The exact resource payloads below are illustrative, but the request pattern is faithful to the FHIR REST behavior Microsoft documents.
PUT https:///Patient/123
Content-Type: application/fhir+json
{
"resourceType": "Patient",
"id": "123",
"active": true
}
PUT https:///Observation/123
Content-Type: application/fhir+json
{
"resourceType": "Observation",
"id": "123",
"status": "final",
"subject": { "reference": "Patient/123" }
}
GET https:///Patient/123
GET https:///Observation/123
GET https:///Patient/123/_history
Before the fix, Microsoft says the latest version “may not be returned as expected,” and the PR says the broken case can surface as HTTP 404 on normal reads. The exact customer-facing exception text for the update collision is not publicly documented, so that detail is best marked as unspecified. What is documented is the underlying cause and the resulting absence of an active version.
From a rollout timeline perspective, the evidence chain is unusually strong. The PR was merged on April 11, 2026. The 4.0.728 release notes on the FHIR server repo call out “Fix data store key comparison” and describe the April 9–11 impact window across affected regions. The Learn release notes then summarize the same issue and fix in the April 2026 monthly release entry.
For operational telemetry, Microsoft’s FHIR service docs say to enable diagnostic settings and send logs to Log Analytics, storage, Event Hubs, or partner sinks. The audit log schema includes fields such as CorrelationId, OperationName, RequestUri, FhirResourceType, StatusCode, and ResultType, and Microsoft provides sample KQL like MicrosoftHealthcareApisAuditLogs | where ResultType == "Failed".
A compact KQL starter for post-incident validation is:
MicrosoftHealthcareApisAuditLogs
| where ResultType == "Failed"
| where TimeGenerated > ago(7d)
| project TimeGenerated, CorrelationId, OperationName, FhirResourceType, RequestUri, StatusCode
| order by TimeGenerated desc
A redacted audit log example, based on Microsoft’s documented sample structure, would look like this:
{
"time": "2026-04-10T14:22:31Z",
"operationName": "Microsoft.HealthcareApis/services/fhir-R4/update",
"category": "AuditLogs",
"resultType": "Failed",
"statusCode": 404,
"correlationId": "9f6a2c2d-",
"uri": "https://-.fhir.azurehealthcareapis.com/Patient/123",
"properties": {
"fhirResourceType": "Patient"
}
}
One more nuance is worth calling out. The PR text says Microsoft’s plan included both a hotfix to stop new occurrences and a follow-on action to reactivate the affected active version for impacted resources. The public release notes do not describe the exact customer-visible remediation flow for previously affected rows, so if a tenant saw April 9–11 anomalies and still has suspicious history behavior, that is a support case, not something to guess through from the outside.
Impact assessment
The blast radius here is not about raw availability only; it is about correctness. If the wrong version is treated as historical, the service can behave as though a perfectly real resource has disappeared from normal reads, or it can fail updates that should be valid. In systems that depend on deterministic FHIR reads for downstream processing, research pipelines, or provider-facing experiences, that is a material incident class.
The fix is also strategically important because it restores a basic invariance: resource identity in the store must be keyed by more than the string ID alone. In FHIR, different resource types legitimately reuse the same resource ID namespace. So the service-side comparison has to understand resource type plus ID together, not one field in isolation. Microsoft’s published fix confirms exactly that shift to ResourceKey.
Mitigation and best practices
If you operate a FHIR workload on Azure, the first practical best practice is to monitor failed reads and updates with correlation IDs turned into support-ready evidence. The audit log schema gives you enough to do that cleanly. When you see sporadic 404 results or update anomalies after imports or high-concurrency bundle ingestion, do not stop at the application tier; check service audit logs by resource type and request URI.
Second, keep a regression test in your integration suite that deliberately uses the same resource ID across different resource types. That is not a weird edge case; it is a valid FHIR shape, and Microsoft’s own fix proves it is the kind of case worth testing. A small CI scenario with Patient/123 and Observation/123, followed by update and history validation, is a good safety net for future platform changes. This recommendation is an engineering inference from Microsoft’s published bug description and PR notes.
Third, if you need to inspect a suspicious record manually, use the _history endpoints and your configured versioning policy rather than relying only on plain GETs. Microsoft’s history and versioning docs make that the right investigative path because history exists precisely to reveal how the resource evolved over time.
Suggested references
- Azure Health Data Services April 2026 release notes with the public bug/fix summary.
- FHIR server release
4.0.728, which documents the April 9–11 impact window and the hotfix. - PR
#5491, which gives the clearest public root-cause description and lists the affected scenarios. - Versioning policy and history management documentation.
- FHIR diagnostic logging and sample audit-log queries.